
Introduction
AI is booming. In 2024, >4000 new AI-related apps were released, with roughly 1.5 billion downloads across all AI-apps (1). From 8 million users of AI apps in H1-2022 to 691 million in three years’ time. AI is used for text and image generation, web searches, fraud detection, compliance, planning, digital personal assistance, etc.
AI is also applied in science and industry, for e.g. process automation, digital twinning, data-driven material discovery and fully automated laboratories. In particular, material discovery is gaining traction, with examples from areas such as pharmaceuticals, batteries, sorbents, catalysts, proteins, additives, and polymers.
The term “Polymer Informatics” was coined some 20 years ago, symbolizing the ‘marriage’ of two scientific fields: data science (informatics) and polymer science. Polymer Informatics deploys AI models (artificial neural networks) to establish structure-property-function relationships for polymers. When appropriately trained, these models are extremely powerful and can be used to design new polymeric materials. Forward design is used to predict polymer properties from novel structures, while inverse design facilitates the prediction of (novel) polymer structures from targeted product specifications. Over the past years, this new discipline has emerged into a global scientific community, with numerous universities, public-private partnerships and various start-ups. Moreover, Polymer Informatics has unlocked innovation potential, as illustrated by some remarkable examples that have already been reported (for e.g. dielectric polymers (2), polymeric membranes (3), conductive polymers (4) and biodegradable polymers(5)).
Hurdles to overcome to unlock the full potential of Polymer Informatics
At the same time, AI isn’t the silver bullet some (polymer) scientists hoped it to be. Despite the enormous gain in computing power, each AI model is… still a model. Yes, a neural network learns patterns in data even the brightest minds did not uncover, but it still needs data. And a lot of it. This is a hurdle for advancing Polymer Informatics as a tool for polymer design. Asking AI, large language models (LLMs) in this case, for additional hurdles, it answers with “modeling of polymers”. Based on our experience, we would like to add a third hurdle: viability – technical, economic, environmental, safety. Let’s unpack these three hurdles to understand what is needed to fully harness AI for polymer design.
Hurdle 1: Data availability & quality determines AI’s predictive performance
As mentioned before, AI-models are data hungry. So, the availability of data is an important aspect of this first hurdle. The quality of that data is another aspect. Compared to the data available to train LLMs (billions of tokens/characters), there is hardly any data available on polymers (100k of datapoints). Furthermore, this data is not available in open libraries, but scattered over various sources and peer-reviewed publications. Another challenge is that various experimental methodologies often exist to determine a single polymer property, attributing to the low quality of the data available. Unfortunately, that’s only the tip of the low-quality iceberg… polymer properties are depending on the molecular weight of the polymer and the polydispersity index (distribution of molecular weight of a polymer). Most peer-reviewed publications that report novel (biobased) polymers only describe a few key polymer properties. This concerns those that can be obtained through relatively simple and low-cost laboratory equipment. Molecular weight and polydispersity index often require larger polymer samples and less standard equipment. As a consequence, hardly any quantitative information on property dependency on molecular weight is available for polymers beyond the few currently used at large scale (PP, PE, PET, PS, PA).
Another data-related hurdle is that polymer properties are changed by formulation of polymers with additives and consequent processing of the formulated polymer into the final product. For example, nucleation agents can be added to accelerate the crystallization during processing. This affects crystallinity and consequently alters other polymer properties (thermal & mechanical) as well. Another formulation example is the use of fillers or fibres that provide reinforcement in structural applications (e.g. construction, automotive). Processing of polymers encompasses extrusion as a first step, while injection moulding, blow moulding, film blowing, or spinning are next processing steps. A beautiful example of the effect of processing on polymer properties is polyethylene: low-density polyethylene (LDPE) is used in film/packaging applications, high-density polyethylene (HDPE) is used for bottles, piping, outdoor furniture, while ultra-high molecular weight polyethylene (UHMWPE) is used as light-weight fibre in cables and defense products. Again, hardly any quantitative information on the effect of formulation and processing is available for polymers beyond the aforementioned bulky ones. These issues with data availability and quality present a significant hurdle in training of meaningful AI-models.
Hurdle 2: Modeling polymers adequately
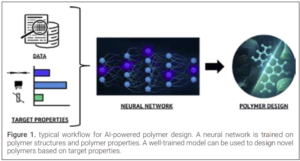
A typical workflow for AI-powered polymer modeling is depicted below. At the heart of this workflow is the Artificial Neural Network (ANN). It learns structure-property-function relationships when properly trained on polymer structures and polymer properties. Where polymer properties are numbers, polymer structures aren’t. This can be solved in a few different ways, using molecular graphs or using SMILES (simplified molecular input line entry system). With molecular graphs, molecules are converted into a graph format where atoms are nodes and bonds are edges. An extra layer needs to be added to the ANN to convert these graphs into numbers. SMILES translate molecules into a text string, which need to be converted into a numerical vector (fingerprint) using a transformer model (LLM). Prof. Ramprasad was among the first to establish a transformer (polyBERT, (6)) for polymer SMILES (PSMILES), allowing the prediction of polymer properties and design of novel polymers.
The second hurdle in Polymer Informatics is adequately modeling the polymers as current models oversimplify the complexity of polymers in different ways.
Firstly, polymers are usually not constructed from just a single monomer (or repeat unit). Polymers with two or more different repeating units are called copolymers. Even in homopolymers, a ‘pinch’ of a different monomer is added during polymerization to obtain the desired properties for a certain application. For example, bottle-grade PET consists for a few percentages of isophthalic acid, while terephthalic acid is the main acidic monomer used in PET. In PET-G, used for PET-trays, part of the ethyleneglycol is replaced by CHDM (cyclohexanedimethanol) to allow for transparent thick-walled trays. Current polymer fingerprinting methods have difficulty representing these homopolymers where ‘pinches’ of other monomers are added to modify polymer properties. In general, fingerprinting of copolymers has proven to be challenging.
Secondly, topology of polymers is of importance as it describes the arrangement of monomers in a polymer chain as well as the spatial (3D) structure of a polymer. The former constitutes random, alternating and blocky polymers, while the latter varies from linear, to branched, cyclic and networked. While polymer topology is pivotal for polymer properties, we can only conclude that it has been proven hard to adequately address this in polymer fingerprints.
Finally, molecular weight and polydispersity of polymers play an important role in determining polymer properties. Some quick-fixes exist to add these aspects as polymer descriptors onto the fingerprinting method. Nevertheless, the lack of data hampers the development of appropriate relationships. Additional representations are needed to capture the impact of molecular weight and polydispersity on especially spatial polymer structures, as illustrated by the UHMWPE example above. So indeed, beyond data, adequately modeling of polymers represents another hurdle for full implementation of Polymer Informatics.
Hurdle 3: Practical viability of polymer designs goes beyond technical performance
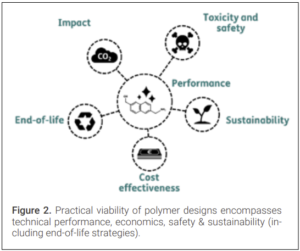
On top of these two main challenges, we should also address the elephant in the room: technical performance alone will not convince boardrooms to invest in novel materials. Current AI-powered models for polymer design have a tunnel vision on performance, but there are other aspects that are of equal or even higher importance. From a practical viability perspective, product safety, value chain sustainability, and cost-competitiveness are important too (Figure 2). AI-models should incorporate these viability aspects as well, to facilitate novel polymers that are safe & sustainable by design (SSbD). The final challenge to overcome is thus to design polymers for practical viability. This allows for acceleration of scale-up, market entry and design from demand (market need).
Opportunities & way forward
To overcome these three main hurdles, various innovations have been presented the past few years. For data, an obvious opportunity would be data sharing across industry, which would result in a high-quality database perfect for model training. There is only one but, and it’s a big one: when all companies share their data, they are actually sharing their intellectual property (IP). So although ideal from a data perspective, this is not going to fly. Rather the opposite, with AI on the rise, companies become more adamant about data security – and they should. Several solutions are being developed for safe data sharing, e.g. federated learning (7), which can be made even more secure through use of blockchain technology.
Another opportunity is the increasing availability of high-throughput (automated/robotized) laboratories, which could be used to generate large datasets. In The Netherlands, a consortium of universities (“BigChemistry”) is developing robotic labs for polymer formulations. In the USA, polyBOT has been developed to process electronic polymers in solution (8). Lila Sciences (USA) is also developing various robotized material platforms, to serve R&D needs of companies (9).
Another strategy is to apply active learning. This modeling feature identifies particular regions within the data space where it is uncertain or lacks sufficient information. It selectively queries for new data points to efficiently improve the AI’s predictive performance. In the context of polymer informatics, this means that new experimental or simulated data can be strategically created for polymers or property ranges where the model’s predictions are least reliable, thus accelerating the discovery of meaningful mechanisms patterns and improving overall predictive capabilities.
Yet another opportunity is introduced by hybrid AI-models (e.g. physics-informed or physics-enforced), that integrate physical laws & principles into the Neural Networks, as such reducing the data hunger of AI-models. These hybrid-AI models also provide solutions for the modeling of polymers, where AI trained on data and physicals laws outperforms conventional AI-models, as beautifully illustrated by prof. Ramprasad and his team (10).
Finally, for viability, several disciplines need to be brought together: data science, polymer science, sustainability, toxicity/safety, engineering (for techno-economic assessments), recycling, biodegradation, etc. Ideally, consortia of universities, research organizations and companies collaboratively establish modellable principles for each of these disciplines. Such modules could then be integrated into regular AI-models for property prediction and serve as additional polymer candidate screening parameters.
Our team at TNO brands our endeavor in the realm of Polymer Informatics as “polySCOUT” (11). We have focused on BigSMILES to include topology into polymer fingerprinting and apply active learning to continuously improve our database with experimental and simulated datasets. Furthermore, we have started to explore how to integrate polymer design with economics, toxicology and sustainability. As such, safe & sustainable design of novel polymers is becoming viable!
References and notes
- Most Popular AI Apps (2025) https://backlinko.com/most-popular-ai-apps
- Gurnani R, et al. AI-assisted discovery of high-temperature dielectrics for energy storage. Nat. Commun. 2024;15(6107).
- Lee YL, et al. Data-driven predictions of complex organic mixture permeation in polymer membranes. Nat. Commun. 2023;14(4931).
- Yoon YW, et al. Explainable machine learning to enable high-throughput electrical conductivity optimization and discovery of doped conjugated polymers. 2024;295(111812).
- Fransen KA, Av-Ron SHM, Buchanan TR, Olsen BD. High-throughput experimentation for discovery of biodegradable polyesters. Proc. Natl. Acad. Sci. U. S. A. 2023;120(e2220021120).
- Kuenneth C, Ramprasad R. polyBERT: a chemical language model to enable fully machine-driven ultrafast polymer informatics. Nat. Commun. 2023;14(4099).
- Yurdem B, Kuzlu M, Gullu MK, Catak FO, Tabassum M. Federated learning: Overview, strategies, applications, tools and future directions. Heliyon. 2024;10(19).
- Wang C, et al. Autonomous platform for solution processing of electronic polymers. Nat. Commun. 2025;16(1498).
- Lila Sciences | Pioneering Scientific Superintelligence https://www.lila.ai/
- Jain A, Gurnani R, Rajan A, Ramprasad R. A physics-enforced neural network to predict polymer melt viscosity. npj Comput Mater. 2025;11(42).
- PolySCOUT – TNO Ventures

